AutoPEFT: Automatic Configuration Search for Parameter-Efficient Fine-Tuning
Abstract
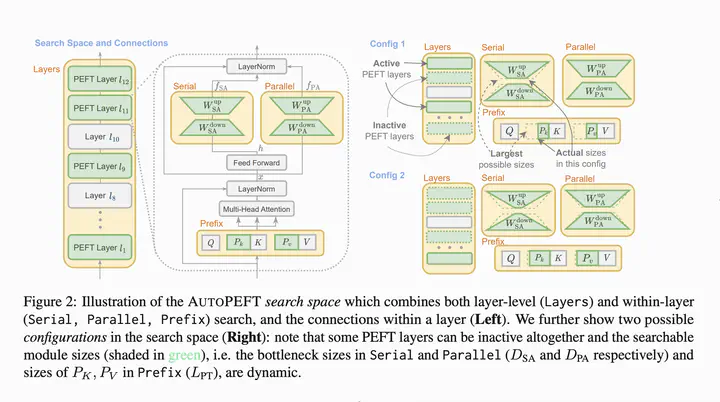
Large pretrained language models have been widely used in downstream NLP tasks via task-specific fine-tuning. Recently, an array of Parameter-Efficient Fine-Tuning (PEFT) methods have also achieved strong task performance while updating a much smaller number of parameters compared to full model tuning. However, it is non-trivial to make informed per-task design choices (i.e., to create PEFT configurations) concerning the selection of PEFT architectures and modules, the number of tunable parameters, and even the layers in which the PEFT modules are inserted. Consequently, it is highly likely that the current, manually set PEFT configurations might be suboptimal for many tasks from the perspective of the performance-to-efficiency trade-off. To address the core question of the PEFT configuration selection that aims to control and maximise the balance between performance and parameter efficiency, we first define a rich configuration search space spanning multiple representative PEFT modules along with finer-grained configuration decisions over the modules (e.g., parameter budget, insertion layer). We then propose AutoPEFT, a novel framework to traverse this configuration space: it automatically configures multiple PEFT modules via high-dimensional Bayesian optimisation. We show the resource scalability and task transferability of AutoPEFT-found configurations, outperforming existing PEFT methods on average on the standard GLUE benchmark while conducting the configuration search on a single task. The per-task AutoPEFT-based configuration search even outperforms full-model fine-tuning.